M.S. in Computer Science
M.S. Thesis: Concept Aware Co-occurrence and its Applications
Co-occurrence of a word is a distribution over words that frequently occur in the same context. Words that frequently co-occurr with the word apple may include (orange, banana, iPhone, iPad, CEO, vitamin), and for the word book may include (title, author, reader, page, ink). Co-occurrence is important for modeling language and can be used in NLP applications.
One limitation of co-occurrence is data sparseness: for a majority of pairs, the probability that they co-occur in even a large corpus could be very small or zero. Another limitation of word co-occurrence is its lack of semantics, there is no explicit relationships between words and concepts (e.g. apple can refer to a company or a fruit concept, depending on the context).
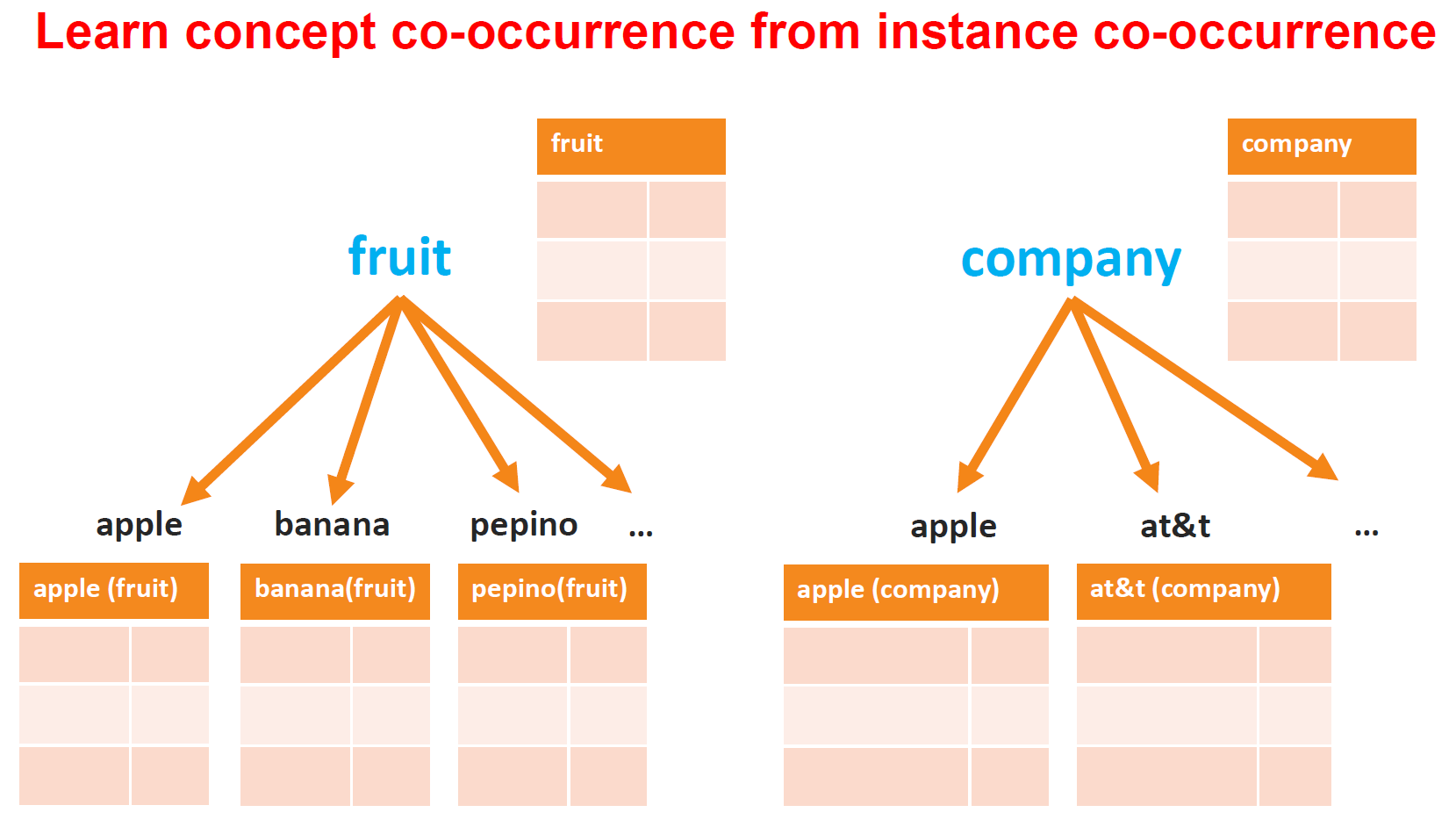
Concept co-occurrence distinguishes the co-occurrence for apple-fruit and apple-company, and then leverages instance co-occurrences to learn concept co-occurrences.
Image on the rigth demonstrates how concept-level representation for fruit and company can be obtained from their instance-level representations.
The process of obtaining concept co-occurrence requires a well-designed NLP pipeline and is computationally intensive: I started with the Common Crawl dataset (more than 2 billion web pages), extracted text from HTML webpages, structured the text by applying tokenization, sentence splitting, POS tagging and dependency parsing, and finnaly extracted the instance and concept co-occurrences. For the instance-concept relations, I used ProBase (Microsot Concept Graph) dataset. I implemented the processing pipeline using Hadoop MapReduce with about 50 machines running for several weeks.
I applied concept co-occurrence to Short Text Understanding problem. I developed a structured prediction model that can segment and disambiguate phrases into concepts with obscure syntax and limited context information.
An output of the model can be seen on the right image, where search queries are first segmented into correct phrases, and then disambiguate with the appropriate concepts.
