Speech Activity Detection for Facebook Videos
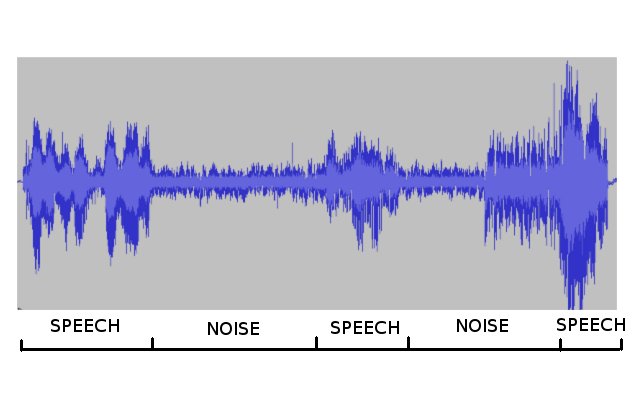
Speech activity detection or voice activity detection (VAD) is a problem of segmenting the audio stream into speech (human voice activity) and non-speech segments (see an example image on the right). It is a critical front-end processing for many speech and audio processing applications. An ideal voice activity detector should be independent from application area and robust to numerous noise conditions.
I developed a novel neural network based speech activity detection model for Facebook videos. The model achieves high accuracy, it is robust to noise conditions and recognizes human speech across all languages that we tested. The model is very fast and is running on a 100% of uploaded Facebook videos, including Facebook Live videos.
We integrated the model into automatic speech recognition (ASR) pipeline, and applied the speech activity detection model prior to ASR to transcribe only speech segments. This reduced the amount of transcribed audio data on Facebook videos by more than 40%, resulting in huge computational and instrastructural savings, without affecting the Word Error Rate.